虚拟币爬虫:数字货币市
2025-10-15
在当今信息化时代,数据已经成为了最重要的资产之一,尤其是在数字货币市场的快速发展中,数据采集变得尤为重要。虚拟币爬虫作为一种自动化的数据抓取工具,能够帮助投资者、分析师和研究者高效地获取虚拟货币相关的实时信息,以便做出决策或者进行深入分析。
虚拟币爬虫是指一种用于自动化抓取虚拟货币相关数据的程序或脚本。这种工具通常利用网络爬虫技术,模拟用户在互联网上浏览的行为,从而获取区块链技术、交易所价格、市场趋势、交易量、新闻报道等信息。
网络爬虫本质上是一个自动化的信息采集技术,它通过 HTTP 请求访问网页,从中提取所需的数据,并将其存储到数据库或文件中。虚拟币爬虫是专门为虚拟币相关网站设计的,它可以自动抓取大量数据,大幅提高数据获取的效率。
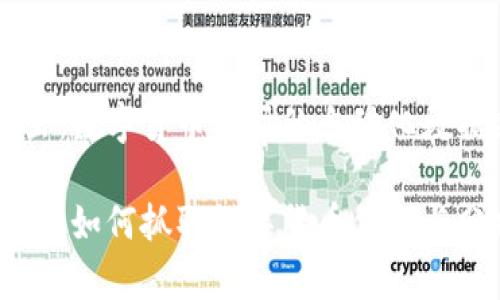
虚拟币爬虫的应用范围相当广泛,以下是几种常见的使用场景:
构建一款有效的虚拟币爬虫需要具备一定的技术基础。以下是一些基本要求:
尽管虚拟币爬虫在数据采集上具有很大的潜力,但在实际操作中也面临着一些挑战:
选择目标网站是构建虚拟币爬虫的第一步,目标网站的选择直接影响到爬虫的效果和效率。以下是一些关键的考虑因素:
在选择网站时,还可以考虑多样性,即不同类型网站的组合使用,如交易所、新闻网站、评级网站等,获取多元化信息。
在进行虚拟币数据抓取时,提高爬虫的抓取效率和准确性非常重要。下面是一些策略:
同时,确保爬取的数据经过必要的验证和校验,避免数据错误或重复,这也是提高准确性的重要环节。
爬取到的虚拟币数据往往需要进一步处理,以下是处理流程及策略:
在数据处理的过程中,应始终保持数据的准确性与完整性,为后续研究和决策提供可靠的依据。
法律风险是每个开发和使用爬虫工具的团队都必须重视的问题。在进行虚拟币爬虫时应考虑以下法律风险:
为了降低法律风险,可以寻求法律建议,了解相关法律法规,并确保在合法框架内进行数据抓取和使用。遵循“爬虫礼仪”,尊重他人的知识产权,是维护自身合法权益的重要保证。
总结而言,虚拟币爬虫作为一种先进的数据采集工具,不仅能够自动化地获取大量的市场数据,还能为投资决策、市场分析和项目监控提供有力的支持。然而,在使用爬虫的同时,也需要注意法律和道德责任,确保所有操作都在法律允许的范围内进行。通过持续爬虫的技术、处理流程,以及对潜在问题的预判,可以更高效、更安全地使用虚拟币爬虫,为数字货币市场的决策提供数据支持。
2025-10-15

2025-10-15

2025-10-15

2025-10-15

2025-10-15

2025-10-14

2025-10-14

2025-10-14

2025-10-14

2025-10-14